На блоге vSphere появилась отличная статья о сервисах семейства vCenter Server Watchdog, которые обеспечивают мониторинг состояния различных компонентов vCenter, а также их восстановление в случае сбоев. Более подробно о них также можно прочитать в VMware vCenter Server 6.0 Availability Guide.
Итак, сервисы Watchdog бывают двух типов:
PID Watchdog - мониторит процессы, запущенные на vCenter Server.
API Watchdog - использует vSphere API для мониторинга функциональности vCenter Server.
Сервисы Watchdog пытаются рестартовать службы vCenter в случае их сбоя, а если это не помогает, то механизм VMware перезагружает виртуальную машину с сервером vCenter на другом хосте ESXi.
PID Watchdog
Эти службы инициализируются во время инициализации самого vCenter. Они мониторят только службы, которые активно работают, и если вы вручную остановили службу vCenter, поднимать он ее не будет. Службы PID Watchdog, контролируют только лишь наличие запущенных процессов, но не гарантируют, что они будут обслуживать запросы (например, vSphere Web Client будет обрабатывать подключения) - этим занимается API Watchdog.
Вот какие сервисы PID Watchdog бывают:
vmware-watchdog - этот watchdog обнаруживает сбои и перезапускает все не-Java службы на сервере vCenter Server Appliance (VCSA).
Java Service Wrapper - этот watchdog обрабатывает сбои всех Java-служб на VCSA и в ОС Windows.
Likewise Service Manager - данный watchdog отвечает за обработку отказов всех не-Java служб сервисов platform services.
Windows Service Control Manager - отвечает за обработку отказов всех не-Java служб на Windows.
vmware-watchdog
Это шелл-скрипт (/usr/bin/watchdog), который располагается на виртуальном модуле VCSA. Давайте посмотрим на его запущенные процессы:
Давайте разберем эти параметры на примере наиболее важной службы VPXD:
-a
-s vpxd
-u 3600
-q 2
Это означает, что:
vpxd (-s vpxd) запущен (started), для него работает мониторинг, и он будет перезапущен максимум дважды в случае сбоя (-q 2). Если это не удастся в третий раз при минимальном аптайме 1 час (-u 3600 - число секунд), виртуальная машина будет перезагружена (-a).
Он основан на Tanuki Java Service Wrapper и нужен, чтобы обнаруживать сбои в Java-службах vCenter (как обычного, так и виртуального модуля vCSA). Вот какие службы мониторятся:
Если Java-приложение или JVM (Java Virtual Machine) падает, то перезапускается JVM и приложение.
Likewise Service Manager
Это сторонние средства Likewise Open stack от компании BeyondTrust, которые мониторят доступность следующих служб, относящихся к Platform Services среды vCenter:
VMware Directory Service (vmdir)
VMware Authentication Framework (vmafd, который содержит хранилище сертификатов VMware Endpoint Certificate Store, VECS)
VMware Certificate Authority (vmca)
Likewise Service Manager следит за этими сервисами и перезапускает их в случае сбоя или если они вываливаются.
mgmt01vc01.sddc.local:~ # /opt/likewise/bin/lwsm list | grep vm vmafd running (standalone: 5505) vmca running (standalone: 5560) vmdir running (standalone: 5600)
Вместо параметра list можно также использовать start и stop, которые помогут в случае, если одна из этих служб начнет подглючивать. Вот полный список параметров Likewise Service Manager:
list List all known services and their status autostart Start all services configured for autostart start-only <service> Start a service start <service> Start a service and all dependencies stop-only <service> Stop a service stop <service> Stop a service and all running dependents restart <service> Restart a service and all running dependents refresh <service> Refresh service's configuration proxy <service> Act as a proxy process for a service info <service> Get information about a service status <service> Get the status of a service gdb <service> Attach gdb to the specified running service
А вот таким образом можно узнать детальную информацию об одном из сервисов:
Помните также, что Likewise Service Manager отслеживает связи служб и гасит/поднимает связанные службы в случае необходимости.
API Watchdog
Этот сервис следит через vSphere API за доступностью самого важного сервиса vCenter - VPXD. В случае сбоя, этот сервис постарается 2 раза перезапустить VPXD, и если это не получится - он вызовет процедуру перезапуска виртуальной машины механизмом VMware HA.
Эти службы инициализируются только после первой загрузки после развертывания или обновления сервисов vCenter. Затем каждые 5 минут через vSphere API происходит аутентификация и опрос свойства rootFolder для корневой папки в окружении vCenter.
Далее работает следующий алгоритм обработки отказов:
Первый отказ = Restart Service
Второй отказ = Restart Service
Третий отказ = Reboot Virtual Machine
Сброс счетчика отказов происходит через 1 час (3600 секунд)
Перед рестартом сервиса VPXD, а также перед перезагрузкой виртуальной машины, служба API Watchdog генерирует лог, который можно исследовать для решения проблем:
storage/core/*.tgz - на виртуальном модуле VCSA
C:\ProgramData\VMware\vCenterServer\data\core\*.tgz - не сервере vCenter
Конфигурация сервиса API Watchdog (который также называется IIAD - Interservice Interrogation and Activation Daemon) хранится в JSON-формате в файле "iiad.json", который можно найти по адресу /etc/vmware/ на VCSA или C:\ProgramData\VMware\vCenterServer\cfg\iiad.json на Windows-сервер vCenter:
requestTimeout – дефолтный таймаут для запросов по умолчанию.
hysteresisCount – позволяет отказам постепенно "устаревать" - каждое такое значение счетчика при отказе, число отсчитываемых отказов будет уменьшено на один.
rebootShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском ВМ.
restartShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском сервиса.
maxTotalFailures – необходимое число отказов по всем службам, которое должно случиться, чтобы произошел перезапуск виртуальной машины.
needShellOnWin – определяет, нужно ли запускать сервис с параметром shell=True на Windows.
watchdogDisabled – позволяет отключить API Watchdog.
vpxd.watchdogDisabled – позволяет отключить API Watchdog для VPXD.
createSupportBundle – нужно ли создавать support-бандл перед перезапуском сервиса или рестартом ВМ.
automaticServiceRestart – нужно ли перезапускать сервис при обнаружении сбоя или просто записать это в лог.
automaticSystemReboot – нужно ли перезапускать ВМ при обнаружении сбоя или просто записать в лог эту рекомендацию.
Многие из вас знают утилиту esxtop (о которой мы часто пишем), позволяющей осуществлять мониторинг производительности сервера VMware ESXi в различных аспектах - процессорные ресурсы, хранилища и сети. Многие администраторы пользуются ей как раз для того, чтобы решать проблемы производительности.
Но оказывается, что использование esxtop само по себе может тормозить работу сервера VMware ESXi!
Это может произойти в ситуации, если у вас к ESXi смонтировано довольно много логических томов LUN, на обнаружение которых требуется более 5 секунд. Дело в том, что esxtop каждые 5 секунд повторно инициализирует объекты, с которых собирает метрики производительности. В случае с инициализацией LUN, которая занимает длительное время, запросы на инициализацию томов будут складываться в очередь. А как следствие (при большом числе томов) это будет приводить к возрастанию нагрузки на CPU и торможению - как вывода esxtop, так и к замедлению работы сервера в целом.
Выход здесь простой - надо использовать esxtop с параметром -l:
# esxtop -l
В этом случае данная утилита ограничит сбор метрик производительности только теми объектами, которые были обнаружены при первом сканировании. Соответственно, так лучше всего ее и использовать, если у вас к серверу VMware ESXi прицеплено много хранилищ.
Некоторое время назад вышло обновление VMware vSphere 6.0 Update 1, после чего пользователи Onyx под Web Client заметили, что он перестал работать. Напомним, что Onyx предназначен для записи действий пользователя в клиенте vSphere, после чего они записываются в виде сценариев PowerShell.
Теперь в обновленном Onyx для VMware vSphere Web Client, который можно скачать с сайта VMware Labs, новая версия vSphere 6.0 U1 полностью поддерживается.
Причина плохого поведения Onyx проста - так как этот продукт теперь полностью завязан на VMware vCenter, то теперь любое значимое изменение оного требует отдельного апдейта.
Таги: VMware, Onyx, Update, Labs, vSphere, Web Client, PowerShell, PowerCLI
Продолжаем рассказывать о новостях компании Veeam Software напрямую с конференции VeeamOn 2015. Напомним, что про нулевой (пре-пати) и первый дни мы писали вот тут и тут.
Второй день конференции был также насыщен событиями, но основное - это, конечно же, анонс президентом кампании Ратмиром Тимашевым бесплатного продукта для резервного копирования данных Linux-систем - Veeam Backup for Linux. Напомним, что несколько ранее компания Veeam выпустила бесплатный Veeam Endpoint Backup Free, который бесплатно позволяет бэкапить данные физических Windows-серверов (для виртуальных есть Veeam Backup and Replication, у которого также есть бесплатное издание).
Не секрет, что администраторы физических Linux-систем бэкапят свои данные чем попало, а, зачастую, и не бэкапят вовсе. Иногда это делается с помощью разных скриптов и костылей, но что с ними происходит, если админ покидает кампанию? Правильно - все приходится начинать заново. Кроме того, есть проблема резервного копирования данных Linux-систем, которые находятся в облаках различных сервис-провайдеров, например, Amazon. Там вообще очень часто все работает без бэкапов.
Так что Veeam Backup for Linux - просто отличный подарок администраторам Linux-систем. Анонс продукта проходил в огромном зале в присутствии COO VMware (он на фото ниже) и нескольких сотен человек, встретивших заявление о бесплатности бэкапа для линукс с большим энтузиазмом.
Veeam Backup for Linux - это решение, работающее на базе агента, который устанавливается в виртуальную или физическую ОС Linux. В качестве основы резервного копирования используется разработанный Veeam драйвер для changed block tracking (CBT).
Продукт Veeam Backup for Linux поддерживает LVM (Logical Volume Manager), но не использует функциональность LVM Snapshot. Вместо этого используется собственный volume snapshot provider, который не имеет таких ограничений, которые есть у LVM. Это позволяет средству от Veeam делать резервные копии множества файловых систем, снимая снапшоты на блочном уровне, при этом данные снапшота находятся на выделенном устройстве хранения, а не на том же томе, с которого идет бэкап. И кроме того, только так получится сделать консистентные снапшоты в среде Linux с помощью Veeam Backup for Linux.
В первой версии решения точно будут поддерживаться ОС Debian и Red Hat, а полный список поддерживаемых линуксов будет опубликован несколько позже.
Основные функции Veeam Backup for Linux:
Возможность настройки бэкапа на различных уровнях - весь сервер целиком, уровень тома или отдельные папки и файлы. Это позволит восстаналивать как полностью сервер, так и отдельные файлы.
Администраторы получат возможность использовать pre-freeze и post-freeze сценарии для подготовки системы к резервному копированию и созданию консистентного бэкапа.
Управлять решением можно будет как из веб-коносли, так и через командную строку и файлы конфигурации.
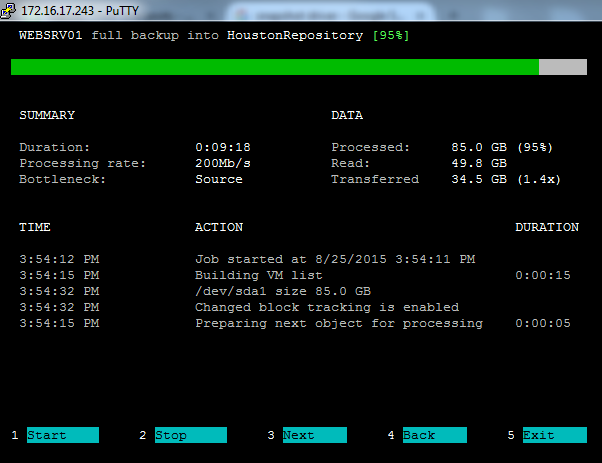
Для тех, кто любит консоль, Veeam сделала минималистичный и приятный дизайн прогресса бэкапа и деталей об этой операции:
Veeam Backup for Linux будет поставляться вместе с SQLite, где будут храниться настройки, статистика и прочее. Не бойтесь: SQLite много ресурсов не будет использовать - только минимальные для решения задач РК.
Veeam Backup for Linux - это бесплатное решение, но если у вас уже есть Veeam Availability Suite или Veeam Backup & Replication, то вы сможете использовать бэкап-репозитории, которые вы добавили в их консолях, в качестве целевых. Это позволит проводить простой мониторинг процесса резервного копирования, получать нотификации по почте об отработавших задачах РК, шифровать файлы в бэкапах и записывать их на ленту, либо в географически удаленную локацию. В общем, все по аналогии с Veeam Endpoint Backup FREE.
Veeam Backup for Linux будет доступен в начале 2016 года. Сейчас вы можете зарегистрироваться на открытую бету - Veeam Backup for Linux beta (кто первый зарегистрируется, тому первому выдадут).
Мы уже не раз писали про VMware ESXi Embedded Host Client, который возвращает полноценный веб-клиент для сервера VMware ESXi с возможностями управления хостом и виртуальными машинами, а также средствами мониторинга производительности.
Теперь для этого продукте есть offline bundle, который можно накатывать с помощью VMware Update Manager, как на VMware vSphere 5.x, так и на VMware vSphere 6.x.
Одна из долгожданных фичей этого релиза - возможность просматривать и редактировать разделы дисков ESXi:
Если у вас есть это средство второй версии, то обновиться на третью можно с помощью следующей команды:
Компания StarWind Software приглашает на бесплатный вебинар "StarWind HyperConverged Appliance: All-Flash Configuration, When Performance is Crucial", который пройдет 27 октября 2015 года в 22-00 по московскому времени. Мероприятие проводит Анатолий Вильчинский, поэтому вы смело можете задавать вопросы на русском языке (самое интересное - это, конечно же, про производительность):
На мероприятии будет рассказано о комплексном решении для хранения данных StarWind HyperConverged Appliance (HA), которе теперь включает в себя конфигурацию All-Flash, то есть все хранилища виртуальных машин размещаются на высокопроизводительных SSD-дисках.
Напомним, что StarWind HyperConverged Appliance строится все это на базе следующих аппаратных платформ (спецификации - тут):
Регистрируйтесь на вебинар, чтобы узнать больше об этом замечательном и недорогом решении для среднего и малого бизнеса.
За прошедшие недели мы достаточно многописали о новостях с VMware VMworld 2015 (как в Америке, так и в Европе). Не так давно компания ИТ-ГРАД, ведущий хостинг-провайдер VMware IaaS в России, опубликовала свою версию основных новостей с VMworld.
Давайте посмотрим, какие анонсы показались коллегам наиболее важными:
15 самых горячих технологических новинок с VMworld 2015
Многие годы VMware формирует будущее корпоративных ИТ-технологий, продвигая идею программно-определяемого ЦОД. Несмотря на растущую конкуренцию, компания до сих пор занимает лидирующие позиции на рынке виртуализации. Столь продвинутую и технически совершенную виртуальную инфраструктуру помогают формировать и многочисленные стратегические партнеры VMware, представившие свои новинки на недавно отгремевшей конференции VMworld 2015. Мы не могли пройти мимо любопытного списка технических новшеств конференции, который опубликовали коллеги из cio.com, и отобрали 15 самых интересных новинок. Спешим поделиться.
1. Unity EdgeConnect
Если попытаться одной фразой объяснить, что делает это устройство, то получится как-то так: Unity EdgeConnect позволяет компаниям упростить и удешевить построение WAN с помощью использования технологий SD-WAN для существующего широкополосного подключения. Фактически требуется подключить такие устройства с обеих сторон (в головном офисе и филиале) и через Unity Orchestrator выполнить связь устройств буквально в пару кликов. Впрочем, лучше посмотреть своими глазами — вот коротенькое видео.
Unity EdgeConnect уже доступен для заказа и обойдется примерно в $199/мес. для каждого сайта.
2. Soha Cloud
Облако Soha Cloud позволяет добавить безопасности вашим облачным приложениям. Продукт выступает в качестве «прослойки» (AirGAP) между облачными приложениями и сетью Интернет, что уменьшает поверхность потенциальной атаки до нуля и прячет приложения от публики. Подробности о технологии можно почерпнуть на сайте SOHA.
Стоимость сервиса стартует с отметки $5/мес. на пользователя, а опробовать его можно уже сейчас.
3. PRTG Network Monitor
PRTG Network Monitor — это система мониторинга для стартапов и небольших компаний. Продукт позволяет выполнять мониторинг состояния и производительности всей инфраструктуры, включая облако и виртуальную среду (например, есть «сенсоры» для серверов VMware и виртуальных машин). Стоимость лицензии зависит от приобретаемого числа сенсоров, причем до 100 штук можно мониторить совершенно бесплатно.
Интересная возможность есть в VMware vSphere 6, которая может оказаться полезной для администраторов датацентров, которые имеют подчиненность главному ЦОД, который задает стандарты администрирования виртуальной инфраструктуры. Возьмем, например, РЖД - у них есть главный вычислительный центр (ГВЦ) и сеть информационно-вычислительных центров (ИВЦ) по всей стране, в которых, как и в ГВЦ, есть свои виртуальные инфраструктуры на платформе VMware vSphere.
Так вот, функция VMware vSphere Content Library позволяет подписать ИВЦ на обновления ГВЦ (который будет издатель/publisher), где можно создать шаблон виртуальной машины, а на уровне ИВЦ (подписчик/subscriber) администраторы этот шаблон ВМ увидят и установят. Очень удобно.
Для этого в центральном датацентре нужно перейти в раздел Content Libraries в vSphere Web Client:
Там нажимаем иконку создания нового объекта и добавляем новую библиотеку (Library):
Далее возьмем виртуальную машину, которую мы хотим превратить в шаблон (VM Template) и выберем из ее контекстного меню пункт Clone -> Clone to Template in Library:
Переходим на вкладку Related Objects и убеждаемся, что шаблон виртуальной машины добавлен в библиотеку:
Теперь, чтобы опубликовать библиотеку (Publish), нужно пойти на вкладку Manage, нажать Edit и поставить галку Publish this library externally (можно задать параметры доступа в разделе Authentication):
Уже в региональном датацентре нужно создать новую библиотеку:
И выбрать пункт Subscribed content library, указав URL центральной библиотеки паблишера:
После этого мы увидим в ней шаблон виртуальной машины, который мы создали в центральном датацентре:
Ну и из этого шаблона мы можем развернуть новую виртуальную машину в нашем региональном ЦОД на базе стандартов центра:
Как вы наверное заметили, помимо вкладки Templates, есть еще и вкладка Other Types, то есть можно публиковать не только шаблоны, но и другие объекты. Наиболее полезно будет распространять таким способом ISO-образы для гостевых ОС, а также скрипты для автоматизации различного рода операций. Удобная штука, но мало кто об этом знает.
Больше 5 лет назад мы писали о технологии VMware Storage I/O Control (SIOC), которая позволяет приоритизировать ввод-вывод для виртуальных машин в рамках хоста, а также обмен данными хостов ESXi с хранилищами, к которым они подключены. С тех пор многие администраторы применяют SIOC в производственной среде, но не все из них понимают, как именно это работает.
На эту тему компания VMware написала два интересных поста (1 и 2), которые на практических примерах объясняют, как работает SIOC. Итак, например, у нас есть вот такая картинка:
В данном случае мы имеем хранилище, отдающее 8000 операций ввода-вывода в секунду (IOPS), к которому подключены 2 сервера ESXi, на каждом из которых размещено 2 виртуальных машины. Для каждой машины заданы параметры L,S и R, обозначающие Limit, Share и Reservation, соответственно.
Напомним, что:
Reservation - это минимально гарантированная производительность канала в операциях ввода-вывода (IOPS). Она выделяется машине безусловно (резервируется для данной машины).
Shares - доля машины в общей полосе всех хостов ESXi.
Limit - верхний предел в IOPS, которые машина может потреблять.
А теперь давайте посмотрим, как будет распределяться пропускная способность канала к хранилищу. Во-первых, посчитаем, как распределены Shares между машинами:
Общий пул Shares = 1000+2500+500+1000 = 5000
Значит каждая машина может рассчитывать на такой процент канала:
Если смотреть с точки зрения хостов, то между ними канал будет поделен следующим образом:
ESX1 = 3500/5000 = 70%
ESX2 = 1500/5000 = 30%
А теперь обратимся к картинке. Допустим у нас машина VM1 простаивает и потребляет только 10 IOPS. В отличие от планировщика, который управляет памятью и ее Shares, планировщик хранилищ (он называется mClock) работает по другому - неиспользуемые иопсы он пускает в дело, несмотря на Reservation у это виртуальной машины. Ведь он в любой момент может выправить ситуацию.
Поэтому у первой машины остаются 1590 IOPS, которые можно отдать другим машинам. В первую очередь, конечно же, они будут распределены на этом хосте ESXi. Смотрим на машину VM2, но у нее есть LIMIT в 5000 IOPS, а она уже получает 4000 IOPS, поэтому ей можно отдать только 1000 IOPS из 1590.
Следовательно, 590 IOPS уйдет на другой хост ESXi, которые там будут поделены в соответствии с Shares виртуальных машин на нем. Таким образом, распределение IOPS по машинам будет таким:
Все просто и прозрачно. Если машина VM1 начнет запрашивать больше канала, планировщик mClock начнет изменять ситуацию и приведет ее к значениям, описанным выше.
В этой заметке мы расскажем еще об одной важной новой функции пакета продуктов - Scale-out Backup Repository. Ранее пользователи Veeam Backup and Replication использовали различные устройства для бэкап-репозиториев, чтобы хранить резервные копии виртуальных машин. Это могли быть локальные диски серверов, файловые хранилища, разделы на СХД и многое другое. Так как инфраструктура растет постепенно и, зачастую, неоднородно, в итоге у администраторов оказывался примерно вот такой наборчик бэкап-репозиториев:
Эта картина плоха со всех сторон. Во-первых, таким большим числом репозиториев трудно управлять - надо следить за их доступностью, поддерживать схемы именования, смотреть за свободным пространством и т.п. Все это создает серьезные административные проблемы в большой инфраструктуре.
Во-вторых, число бэкап-задач, которые создает администратор - как минимум равно числу бэкап-репозиториев, так как одна задача не может охватывать 2 репозитория.
Ну и, в третьих, посмотрите на свободное место на каждом репозитории - его весьма много (если брать среднее, то 30%). То есть, мы используем вполовину больше того, что нам требуется.
Эта ситуация давно волновала администраторов, и в новой версии Veeam Availability Suite v9 представлена функция Scale-out Backup Repository, которая позволяет объединить все репозитории в один мета-объект (global pool), который можно задавать в качестве целевого хранилища бэкапов. Для расширения такого пула потребуется лишь добавить экстент (extent), который повысит совокупную емкость глобального репозитория. Удобно и не надо перераспределять целевые хранилища, чтобы найти свободное место под новые бэкапы.
Таким образом, можно использовать единственную задачу резервного копирования всех нужных вам машин, указав в качестве целевого этот глобальный репозиторий. При этом глобальный репозиторий можно наращивать хранилищами любого типа - локальные диски серверов, сетевые хранилища и даже, например, дедуплицирующие физические или виртуальные модули (dedup appliances) - все это для Veeam Backup and Replication будет поддерживаться и работать.
При добавлении экстента можно указать, принимает ли он полные бэкапы (full backups), инкрементальные бэкапы (incremental backups) или оба типа. Например, для инкрементальных бэкапов можно использовать быстрые all-flash хранилища, а для полных бэкапов можно применять dedup appliance в качестве целевого хранилища резервных копий, где они будут лежать в дедуплицированном виде. Возможности для фантазии тут безграничны.
Также происходит, по-сути, появление бэкап-облака, нового уровня абстракции, которое представляется пользователям как единое пространство хранения резервных копий, а его обслуживанием занимается бэкап-администратор. Теперь владельцы систем могут сами настраивать бэкап своих виртуальных машин в единое облако, не думая, какой репозиторий выбрать, а бэкап-администратор уже займется оптимизацией своего облака.
Более подробно об этом всем написано в блоге Veeam.
Тема вебинара - "Защита виртуальных инфраструктур: комбинация встроенных механизмов платформы виртуализации и сторонних средств". Мероприятие проведет Иван Колегов, системный аналитик компании «Код Безопасности». На вебинаре будет рассказано о защите виртуальных инфраструктур с помощью встроенных механизмов платформы виртуализации и сторонних средств. Таги:
Бывает так, что на виртуальной или физической машине заканчивается свободное место на диске, где расположена база данных для VMware vCenter. Чаще всего причина проста - когда-то давно кто-то не рассчитал размер выделенного дискового пространства для сервера, где установлен vCenter и SQL Server Express.
В этом случае в логах (в SQL Event Log Viewer и SQL Log) будут такие ошибки:
Could not allocate space for object ‘dbo.VPX_EVENT_ARG’.’PK_VPX_EVENT_ARG’ in database ‘VIM_VCDB’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.
CREATE DATABASE or ALTER DATABASE failed because the resulting cumulative database size would exceed your licensed limit of 4096 MB per database.
Could not allocate space for object 'dbo.VE_event_historical'.'PK__VE_event_histori__00551192' in database 'ViewEvent' because the 'PRIMARY' filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files tothe filegroup, or setting autogrowth on for existing files in the filegroup.
Решение в данном случае простое - нужно выполнить операцию по очистке старых данных из БД SQL Server (Shrink Database). Делается это в SQL Management Studio - нужно выбрать базу данных и выполнить Tasks -> Shrink -> Database:
Смотрим, что получится и нажимаем Ok:
Также в KB 1025914 вы найдете более детальную информацию о том, как почистить базы данных Microsoft SQL Server и Oracle. Там же есть и скрипты очистки БД:
Мы часто пишем о проблемах вложенной виртуализации (nested virtualization), которая представляет собой способ запустить виртуальные машины на гипервизоре, который сам установлен в виртуальной машине. На платформе VMware ESXi эта проблема давно решена, и там nested virtualization работает уже давно, мало того - для виртуального ESXi есть даже свои VMware Tools.
Как мы недавно писали, решения для вложенной виртуализации на платформе Microsoft Hyper-V не было. При попытке запустить виртуальную машину на виртуальном хосте Hyper-V администраторы получали вот такую ошибку:
VM failed to start. Failed to start the virtual machine because one of the Hyper-V components is not running.
Все это происходило из-за того, что Microsoft не хотела предоставлять виртуальным машинам средства эмуляции техник аппаратной виртуализации Intel VT и AMD-V. Стандартная схема виртуализации Hyper-V выглядела так:
Virtualization Extensions передавались только гипервизору хостовой ОС, но не гостевой ОС виртуальной машины. А без этих расширений виртуальные машины в гостевой ОС запущены быть не могли.
Соответственно, это позволит запустить вложенные виртуальные машины на хосте, который сам является виртуальной машиной с гостевой ОС Windows и включенной ролью Hyper-V.
На данный момент работает это только с Intel VT, но по идее к релизу Windows Server 2016 должно заработать и для AMD-V.
Сфера применения вложенных виртуальных машин не такая уж и узкая. Сейчас видится 2 основных направления:
Виртуальные тестовые лаборатории, где развертываются виртуальные серверы Hyper-V и строятся модели работающих виртуальных инфраструктур в рамках одного физического компьютера.
Использование контейнеризованных приложений (например, на движке Docker) в виртуальных машинах на виртуальных хостах Hyper-V. Более подробно о Windows Server Containers можно почитать вот тут. Немногим ранее мы писали об аналогичной архитектуре на базе VMware vSphere, анонсированной на VMware VMworld 2015.
Надо отметить, что для вложенных виртуальных машин не поддерживаются следующие операции (как минимум):
Dynamic Memory
Горячее изменение памяти работающей ВМ
Снапшоты
Live Migration
Операции save/restore
Ну и вообще, вряд ли вложенная виртуализация вообще когда-нибудь будет полностью поддерживаться в производственной среде. Кстати, вложенная виртуализация на сторонних гипервизорах (например, VMware vSphere) также не поддерживается.
Для того, чтобы вложенная виртуализация заработала, нужно:
1. Использовать Windows 10 Build 10565. Windows Server 2016 Technical Preview 3 (TPv3) и Windows 10 GA - не подойдут, так как в них возможности Nested Virtualization нет.
2. Включить Mac Spoofing на сетевом адаптере виртуального хоста Hyper-V, так как виртуальный коммутатор хостового Hyper-V будет видеть несколько MAC-адресов с этого виртуального адаптера.
3. В Windows 10 нужно отключить фичу Virtualization Based Security (VBS), которая предотвращает трансляцию Virtualization Extensions в виртуальные машины.
4. Предусмотреть память под сам гостевой гипервизор и под все запущенные виртуальные машины. Память для гипервизора можно рассчитать так:
Теперь для того чтобы включить Nested Virtualization, выполните следующий сценарий PowerShell (в нем и VBS отключается, и Mac Spoofing включается):
Далее создайте виртуальную машину на базе Windows 10 Build 10565, и включите в ней Mac Spoofing (если вы не сделали это в скрипте). Сделать это можно через настройки ВМ или следующей командой PowerShell:
Set-VMNetworkAdapter -VMName <VMName> -MacAddressSpoofing on
Ну а дальше просто запускайте виртуальную машину на виртуальном хосте Hyper-V:
Таги: Microsoft, Hyper-V, Nested, Virtualization, VMachines, Windows, Server
После выхода новой версии платформы VMware vSphere 6 перед многими администраторами встал вопрос об обновлении различных компонентов виртуальной инфраструктуры. На крупных предприятиях, как правило, используется не только платформа VMware ESXi и сервисы управления vCenter, но и различные корпоративные продукты, такие как VMware Horizon View для инфраструктуры виртуальных ПК или VMware vRealize Operations (vROPs) для мониторинга и решения проблем.
Вот в какой правильной последовательности нужно обновлять решения VMware (если у нескольких продуктов очередь одна - их можно обновлять в любой последовательности):
Продукт
VMware
Последовательность обновления (очередность)
vCenter
Single Sign-On (SSO)
1
vRealize Automation (vRA), бывший vCloud Automation Center
2
vRealize Configuration Manager (VCM), бывший vCenter Configuration Manager
2
vRealize Business (он же ITBM - VMware IT Business Management)
2
vRealize Automation Application Services (vRAS), бывший vSphere AppDirector
3
vCloud Director (vCD)
3
vCloud Networking and Security (vCNS)
4
NSX Manager
4
NSX Controllers
5
View Composer
5
View Connection Server
6
vCenter Server
7
vRealize Orchestrator (vRO), он же vCenter Orchestrator
8
vSphere Replication (VR)
8
vCenter Update Manager (VUM)
8
vRealize Operations Manager (vROPs) / он же vCenter Operations Manager (vCOPs)
8
vSphere Data Protection (VDP)
8
vCenter Hyperic
8
vCenter Infrastructure Navigator (VIN)
8
vCloud Connector (vCC)
9
vRealize Log Insight (vRLI)
9
vSphere Big Data Extension (BDE)
9
vCenter Site Recovery Manager (SRM)
9
ESXi
10
VMware Tools
11
vShield / NSX / Edge
11
vShield App/ NSX LFw
12
vShield Endpoint / NSX Guest IDS
12
View Agent / Client
12
О проведении операций по обновлению компонентов решений VMware более подробно рассказано в статье KB 2109760. Там же приведены примеры сценариев обновления, если у вас есть определенный набор продуктов.
Кстати, помните, что после обновления на VMware vSphere 6.0 вы не сможете использовать продукт VMware Storage Appliance, который больше не поддерживается.
Этой статьёй я хочу открыть серию статей, целью каждой из которых будет описание одной из написанных мной функций PowerCLI или так называемых командлетов (cmdlets), предназначенных для решения задач в виртуальных инфраструктурах, которые невозможно полноценно осуществить с помощью только лишь встроенных функций PowerCLI. Все эти функции будут объединены в один модуль - Vi-Module. Как им пользоваться, можете почитать здесь.
15 октября в 15:00 ИТ-ГРАД проводит презентацию новых высокопроизводительных флеш-массивов AFF от NetApp. На мероприятии вы узнаете о новой расширенной линейке флеш-массивов СХД, разработанной для корпоративных клиентов. Спикерами мероприятия выступят инженеры NetApp и ИТ-ГРАД. Таги:
Мы часто рассказываем о решении vGate R2 от компании Код Безопасности, предназначенном для защиты виртуальной инфраструктуры VMware vSphere и Microsoft Hyper-V от несанкционированного доступа, а также для ее безопасной настройки средствами политик.
Не так давно мы писали о новых возможностях vGate 2.8, а ниже расскажем о реальном использовании продукта в производственной среде организации, работающей с чувствительными данными.
Компания «Код Безопасности», российский разработчик программных и аппаратных средств защиты, сообщает о реализации проекта по внедрению средства защиты vGate в центре обработки данных (ЦОД) «Электронного правительства» Ленинградской области.
Заказчиком проекта выступил Комитет по телекоммуникациям и информатизации Ленинградской области; работы по внедрению продукта осуществлялись при участии специалистов ГКУ ЛО «Оператор электронного правительства». Поставка средства защиты информации vGate была реализована партнером «Кода Безопасности» в Северо-Западном федеральном округе – Группой компаний SuperWave.
Центр обработки данных правительства Ленинградской области представляет собой виртуализированный кластер, построенный на современной платформе VMware vSphere. В ЦОДе функционируют различные информационные системы исполнительных органов государственной власти Ленобласти, в том числе портал государственных и муниципальных услуг, система обеспечения деятельности региональных МФЦ, бухгалтерские и учетные системы, системы ЭДО, базы данных CRM-систем и пр. В этих государственных информационных системах хранятся и обрабатываются персональные данные и другая конфиденциальная информация. vGate R2 обеспечивает сертифицированную защиту этой информации и позволяет привести виртуальную инфраструктуру в соответствие требованиям приказов ФСТЭК России № 17 и № 21 и подготовить систему к прохождению аттестации.
«Перед началом проекта был сформирован список основных требований к системе защиты ЦОДа правительства Ленинградской области. Мы искали решение, которое сертифицировано по требованиям ФСТЭК России, поддерживает работу с платформой VMware, реализует защиту исключительно программными средствами, имеет развитый функционал и различные механизмы обеспечения безопасности в виртуальной инфраструктуре. vGate оказался единственным решением, удовлетворяющим всем нашим требованиям» – рассказал директор ГКУ ЛО «ОЭП», Кораблев Михаил Анатольевич.
Более подробно узнать о продукте vGate R2 и скачать его актуальную версию можно по этой ссылке.
Как вы знаете, некоторое время назад компания VMware выпустила обновление платформы виртуализации vSphere 6 Update 1. После его выхода компания Veeam предупредила пользователей, что средство резервного копирования виртуальных машин Veeam Backup & Replication 8.0 пока не поддерживает последнее обновление от VMware. И вот на днях вышел Veeam Backup & Replication 8.0 Update 3с полной поддержкой vSphere 6 Update 1. Так что большинство пользователей платформы ESXi может смело обновлять свою инфраструктуру.
Посмотрим на все новые возможности последнего обновления Veeam B&R:
Улучшения для Microsoft Windows:
Поддержка Windows 10 в качестве гостевой ОС (включая обработку приложений - application-aware processing).
Поддержка установки Veeam Backup & Replication и всех его компонентов на Windows 10.
Улучшения для VMware vSphere:
Поддержка vSphere 6.0 Update 1.
Возможность превратить предупреждение "VMware Tools not found" в информационное сообщение. Для этого параметр DisableVMwareToolsNotFoundWarning (REG_DWORD) в реестре нужно установить в значение 1.
Улучшения для Linux:
Поддержка SSH-шифрования: aes128-ctr, aes192-ctr, aes256-ctr, aes192-cbc и aes256-cbc.
Новое у Veeam Explorer for Microsoft SQL Server:
Лог транзакций для неподдерживаемых экземпляров SQL Server автоматически игнорируется, чтобы избежать сообщений об ошибке.
Предпочитаемые сетевые настройки также применяются к задачам бэкапа транзакционного лога.
Новое у Veeam Explorer for SharePoint:
Поддержка аутентификации ADFS
Поддержка UPN credentials.
Улучшения SureBackup
Модуль Proxy appliance теперь отвечает на пинг внутри виртуальной лаборатории (Virtual Lab), чтобы сетевые экраны не блокировали автоматически ее сеть как публичную.
Другое:
Улучшено шифрование.
Улучшена производительность операций консоли в больших окружениях.
Уменьшена нагрузка на сервер SQL, а также увеличена надежность.
Увеличена производительность настройки конфигурации резервного копирования для больших окружений.
Прочие исправления ошибок в различных областях.
Скачать Veeam Backup & Replication 8.0 Update 3 можно по этой ссылке (нужно залогиниться).
В конце прошлой недели компания Citrix выпустила обновления для своих флагманских продуктов - Feature Pack 3 for XenApp and XenDesktop 7.6. Напомним, что о новых возможностях новых версий этих решений мы писали вот тут.
О возможностях второго фиче-пака можно прочитать вот тут, а про первый написано здесь. Кроме того, на эту тему есть специальный FAQ.
Новые возможности Feature Pack 3 for XenApp and XenDesktop 7.6:
Новый Windows Workstation Virtual Delivery Agent (VDA), который упрощает развертывание новых ПК (в том числе, на базе Windows 10), а также их миграцию на Windows 10.
Citrix Receiver for Windows 10 - новая версия ПО для доступа к опубликованным приложениям XenApp/XenDesktop.
Новая версия Citrix AppDNA 7.6.5 - средства, упрощающего миграцию на Windows 10 путем виртуализации физически установленных у пользователей приложений.
Существенные улучшения производительности, в том числе технологии Thinwire, отвечающей за отображение пользовательского окружения на тонких клиентах.
Улучшенные шаблоны HDX Policy Templates, касающиеся настроек доставки пользователям интерфейса приложений и десктопов. Также доступны новые наборы преконфигурированных шаблонов.
Улучшения Universal Print Server, который теперь доступен и для Windows Server 2012 R2, а также поддержка клиентов Windows 10.
Аутентификация по смарт-картам стала работать на 25% быстрее.
Появилась политика Restrict Access from Jailbroken Devices, позволяющая предотвращать доступ с джейлбрейкнутых устройств.
Технология HDX MediaStream может проверять соответствие версий Flash на клиенте и сервере во избежание проблем совместимости.
Улучшенная поддержка планшетов для рисования (Wacom), включая средства для цифровой подписи контента с помощью смарт-карт.
Мы уже писали о новой версии решения VMware Virtual SAN 6.1, предназначенной для создания отказоустойчивых хранилищ на платформе VMware vSphere. После того, как издания "hybrid" и "all-flash" были переименованы в "standard" и "advanced" соответственно, у пользователей появилось несколько вопросов о функциональности этих изданий.
Начнем с того, что в целом все осталось как было:
VSAN
STANDARD
VSAN
ADVANCED
VSAN FOR ROBO
(25 VM PACK)
Политики хранилищ Storage Policy Based Management (SPBM)
Итак, мы видим, что отличий у изданий Standard и Advanced теперь два:
Для конфигураций только из SSD-дисков серверов можно использовать только издание Advanced.
Для "растянутых" кластеров также можно использовать только издание Advanced. Но тут есть нюанс - растянутым кластером можно считать географически разнесенные площадки (на уровне двух разных зданий). Если у вас кластер на уровне стоек в двух серверных или на разных этажах - растянутым он не считается.
Также появилось издание VSAN for ROBO (remote or branch offices). Это издание позволяет использовать решение VSAN компаниям имеющую сеть небольших филиалов, где нет большого числа хостов ESXi. Для такой лицензии можно запустить не более 25 виртуальных машин в рамках филиала и одной ROBO-лицензии.
Здесь кластеры строятся на уровне каждого из филиалов, а witness-компонент (виртуальный модуль, следящий за состоянием кластера) располагается в инфраструктуре центрального офиса. Причем на каждый кластер VSAN нужно по отдельному witness'у. Этот самый witness позволяет построить кластер на базе всего двух узлов, а не трех, так как он следит за ситуацией split brain в кластере. Это позволяет удешевить решение для филиала, использовав для инфраструктуры из 25 машин всего 2 сервера. Более подробно о ROBO-сценарии написано вот тут.
А вот как выглядит настройка ROBO-издания Virtual SAN:
Ну и, само собой, ROBO-сценарии можно реализовывать по своему усмотрению на лицензиях Standard или Advanced.
Мы уже немало писали про технологию использования хранилищ VVols (например, здесь и здесь), которая позволяет существенно увеличить производительность операций по работе с хранилищами в среде VMware vSphere за счет использования отдельных логических томов под компоненты виртуальных машин и передачи части операций по работе с ними на сторону дисковых массивов.
Давайте посмотрим, как же технология VVols влияет на процесс резервного копирования виртуальных машин, например, с помощью основного продукта для бэкапа ВМ Veeam Backup and Replication, который полностью поддерживает VVols. Для начала рассмотрим основные способы резервного копирования, которые есть в виртуальной среде:
Резервное копирование за счет монтирования виртуальных дисков (Hot Add backup) - в этом случае к одной ВМ монтируется диск VMDK другой ВМ и происходит его резервное копирование
Резервное копирование по сети передачи данных (NBD backup) - это обычное резервное копирование ВМ по сети Ethernet, когда снимается снапшот ВМ (команды отдаются хостом ESXi), основной диск передается на бэкап таргет, а потом снапшот применяется к основному диску ("склеивается" с ним) и машина продолжает работать как раньше.
Резервное копирование по сети SAN (SAN-to-SAN backup) - в этом случае на выделенном сервере (Backup Server) через специальный механизм Virtual Disk API происходит снятие снапшота ВМ без задействования хоста ESXi и бэкап машины на целевое хранилище напрямую в сети SAN без задействования среды Ethernet.
Последний способ - самый быстрый и эффективный, но он требует наличия специальных интерфейсов (vSphere APIs и Virtual Disk Development Kit, VDDK), которые должны присутствовать на выделенном сервере.
К сожалению, для VVols способ резервного копирования по сети SAN еще не поддерживается, так как данный механизм для прямой работы с хранилищами SAN для VVols еще не разработан. Поэтому при работе с VVols придется использовать NBD backup. Однако не расстраивайтесь - большинство компаний именно его и используют для резервного копирования машин на томах VMFS в силу различных причин.
Работа хоста VMware ESXi с томами виртуальной машины VVols выглядит следующим образом:
Для процессинга операций используется Protocol Endpoint (PE), который представляет собой специальный административный LUN на хранилище. PE работает с лунами машин (VVols), которые представлены через secondary LUN ID, а VASA Provider со стороны дискового массива снабжает vCenter информацией о саблунах виртуальных машин, чтобы хост ESXi мог с ними работать через PE.
Таким образом, в новой архитектуре VVols пока не прикрутили технологический процесс соединения стороннего сервера с VVols виртуальных машин и снятия с них резервных копий.
Вернемся к процессу резервного копирования. Как известно, он опирается на механизм работы снапшотов (Snapshots) - перед снятием резервной копии у ВМ делается снапшот, который позволяет перевести базовый диск в Read Only, а изменения писать в дельта-диск снапшота. Далее базовый диск ВМ копируется бэкап-сервером, ну а после того, как базовый диск скопирован, снапшот склеивается с основным диском, возвращая диски машины обратно в консолидированное состояние.
Так это работает для файловой системы VMFS, которая развертывается поверх LUN дискового массива. Сами понимаете, что при интенсивной нагрузке во время резервного копирования (особенно больших виртуальных дисков) с момента снятия снапшота может пройти довольно много времени. Поэтому в дельта-дисках может накопиться много данных, и процесс консолидации снапшота на практике иногда занимает часы!
Для виртуальных томов VVols все работает несколько иначе. Давайте взглянем на видео:
В среде VVols при снятии снапшота базовый диск остается режиме Read/Write (это все делает массив), то есть контекст записи данных никуда не переключается, и изменения пишутся в базовый диск. В снапшоты (это отдельные тома VVol) пишется только информация об изменениях базового диска (какие дисковые блоки были изменены с момента снятия снапшота).
Ну а при удалении снапшота по окончанию резервного копирования никакой консолидации с базовым диском производить не требуется - так как мы продолжаем с ним работать, просто отбрасывая дельта-диски.
Такой рабочий процесс несколько увеличивает время создания снапшота в среде VVols:
Но это всего лишь десятки секунд разницы. А вот время консолидации снапшота по окончанию резервного копирования уменьшается во много раз:
Как следствие, мы имеем уменьшение совокупного времени резервного копирования до 30%:
Так что, если говорить с точки зрения резервного копирования виртуальных машин, переход на VVols обязательно даст вам прирост производительности операций резервного копирования и позволит уменьшить ваше окно РК.
Недавно мы писали том, что компания Код Безопасности, производитель решений номер 1 для защиты виртуальных сред, выпустила обновление продукта vGate R2 версии 2.8. Эта версия прошла инспекционный контроль в ФСТЭК России и доступна для загрузки и покупки. В обновленную версию vGate R2 добавлены новые механизмы защиты и расширенные функции по администрированию системы. Сегодня мы расскажем о том, как в vGate R2 выглядит рабочий процесс для пользователей в защищенной среде.
Интересный пост, касающийся поддержки VMware Tools в смешнном окружении, опубликовали на блогах VMware. Если вы взглянете на папку productLocker в ESXi, то увидите там 2 подпапки /vmtools и /floppies:
Это файлы, относящиеся к пакету VMware Tools, устанавливаемому в гостевые ОС виртуальных машин. Перейдем в папку /vmtools:
Тут находится куча ISO-образов с данными пакета (каждый под нужную гостевую ОС), файл манифеста, описывающий имена, версии и ресурсы файлов пакета, а также сигнатура ISO-шки с тулзами, позволяющая убедиться, что она не была изменена.
В папке floppies находятся виртуальные образы дискет, которые могут понадобиться для специфических гостевых ОС при установке драйверов (например, драйвер устройства Paravirtual SCSI):
Интересно, что папка productLocker занимает примерно 150 МБ, что составляет где-то половину от размера установки VMware ESXi. Именно поэтому рекомендуют использовать образ ESXi без VMware Tools ("no-tools") при использовании механизма Auto Deploy для массового развертывания хост-серверов.
Самая соль в том, что версия пакета VMware Tools на каждом хосте разная и зависит от версии VMware ESXi. Например, мы поставили на хосте VMware vSphere 5.5 виртуальную машину и установили в ней тулзы. Консоль vCenter покажет нам, что установлена последняя версия VMware Tools:
Однако если у нас смешанная инфраструктура (то есть, состоит их хостов разных версий), то при перемещении машины на хост с более высокой версией, например, vSphere 5.5 Update 2/3, она будет показана как ВМ с устаревшей версией пакета (VMware Tools: Running (Out-of-Date):
Поэтому возникает некоторая проблема в смешанной среде, которую можно решить очень просто - как правило VMware Tools от хоста с большей версией подходят ко всем предыдущим. Например, тулзы от vSphere 6.0 подойдут ко всем хостам до ESXi 4.0 включительно. vSphere 6 Update 1 выпадает из списка (постепенно поддержка старых версий уходит):
Таким образом, лучше всего распространить тулзы от vSphere 6 на все хосты вашей виртуальной инфраструктуры. Для этого создадим общий для всех хостов датастор SDT и через PowerCLI проверим, что к нему имеет доступ несколько хостов, командой:
Get-Datastore | where {$_.ExtensionData.summary.MultipleHostAccess -eq “true”}
Далее создадим на этом датасторе папку productLocker:
в которую положим VMware Tools от ESXi 6.0:
Далее нужно пойти в раздел:
Manage > Settings > Advanced System Settings > UserVars.ProductLockerLocation
и вбить туда путь к общей папке, в нашем случае такой:
/vmfs/volumes/SDT/productLocker
Если вы хотите применить эту настройку сразу же на всех хостах кластера, то можно использовать следующий командлет PowerCLI:
Теперь для применения настроек есть два пути: первый - это перезапустить хост ESXi, но если вы этого сделать не можете, то есть и второй путь - выполнить несколько команд по SSH.
Зайдем на хост ESXi через PuTTY и перейдем в папку с /productLocker командой cd. Вы увидите путь к локальной папке с тулзами на хосте, так как это ярлык:
Удалим этот ярлык:
rm /productLocker
После чего создадим новый ярлык на общую папку на томе VMFS с тулзами от vSphere 6.0:
Вот таким вот образом можно поддерживать самую последнюю версию VMware Tools в виртуальных машинах, когда в вашей производственной среде используются различные версии VMware ESXi.
Недавно Cormac Hogan написал интересный пост о том, как нужно настраивать "растянутый" между двумя площадками HA-кластер на платформе VMware vSphere, которая использует отказоустойчивую архитектуру Virtual SAN.
Напомним, как это должно выглядеть (два сайта на разнесенных площадках и witness-хост, который обрабатывает ситуации разделения площадок):
Основная идея такой конфигурации в том, что при отказе отдельного хоста или его компонентов виртуальная машина обязательно должна запуститься на той же площадке, где и была до этого, а в случае отказа всей площадки (аварии) - машины должны быть автоматически запущены на резервном сайте.
Откроем настройки кластера HA. Во-первых, он должен быть включен (Turn on vSphere HA), и средства обнаружения сетевых отказов кластера (Host Monitoring) также должны быть включены:
Host Monitoring позволяет хостам кластера обмениваться сигналами доступности (heartbeats) и в случае отказа предпринимать определенные действия с виртуальными машинами отказавшего хоста.
Для того, чтобы виртуальная машина всегда находилась на своей площадке в случае отказа хоста (и использовала локальные копии данных на виртуальных дисках VMDK), нужно создать Affinity Rules, которые определяют правила перезапуска ВМ на определенных группах хостов в рамках соответствующей площадки. При этом эти правила должны быть "Soft" (так называемые should rules), то есть они будут соблюдаться при возможности, но при отказе всей площадки они будут нарушены, чтобы запустить машины на резервном сайте.
Далее переходим к настройке "Host Hardware Monitoring - VM Component Protection":
На данный момент кластер VSAN не поддерживает VMCP (VM Component Protection), поэтому данную настройку надо оставить выключенной. Напомним, что VMCP - это новая функция VMware vSphere 6.0, которая позволяет восстанавливать виртуальные машины на хранилищах, которые попали в состояние All Paths Down (APD) или Permanent Device Loss (PDL). Соответственно, все что касается APD и PDL будет выставлено в Disabled:
Теперь посмотрим на картинку выше - следующей опцией идет Virtual Machine Monitoring - механизм, перезапускающий виртуальную машину в случае отсутствия сигналов от VMware Tools. Ее можно использовать или нет по вашему усмотрению - оба варианта полностью поддерживаются.
На этой же кариинке мы видим настройки Host Isolation и Responce for Host Isolation - это действие, которое будет предпринято в случае, если хост обнаруживает себя изолированным от основной сети управления. Тут VMware однозначно рекомендует выставить действие "Power off and restart VMs", чтобы в случае отделения хоста от основной сети он самостоятельно погасил виртуальные машины, а мастер-хост кластера HA дал команду на ее восстановление на одном из полноценных хостов.
Далее идут настройки Admission Control:
Здесь VMware настоятельно рекомендует использовать Admission Control по простой причине - для растянутых кластеров характерно требование самого высокого уровня доступности (для этого он, как правило, и создается), поэтому логично гарантировать ресурсы для запуска виртуальных машин в случае отказа всей площадки. То есть правильно было бы зарезервировать 50% ресурсов по памяти и процессору. Но можно и не гарантировать прям все 100% ресурсов в случае сбоя, поэтому можно здесь поставить 30-50%, в зависимости от требований и условий работы ваших рабочих нагрузок в виртуальных машинах.
Далее идет настройка Datastore for Heartbeating:
Тут все просто - кластер Virtual SAN не поддерживает использование Datastore for Heartbeating, но такого варианта тут нет :) Поэтому надо выставить вариант "Use datastores only from the secified list" и ничего из списка не выбирать (убедиться, что ничего не выбрано). В этом случае вы получите сообщение "number of vSphere HA heartbeat datastore for this host is 0, which is less than required:2".
Убрать его можно по инструкции в KB 2004739, установив расширенную настройку кластера das.ignoreInsufficientHbDatastore = true.
Далее нужно обязательно установить кое-какие Advanced Options. Так как кластер у нас растянутый, то для обнаружения наступления события изоляции нужно использовать как минимум 2 адреса - по одному на каждой площадке, поэтому расширенная настройка das.usedefaultisolationaddress должна быть установлена в значение false. Ну и нужно добавить IP-адреса хостов, которые будут пинговаться на наступление изоляции хост-серверов VMware ESXi - это настройки das.isolationaddress0 и das.isolationaddress1.
Таким образом мы получаем следующие рекомендуемые настройки растянутого кластера HA совместно с кластером Virtual SAN:
vSphere HA
Turn on
Host Monitoring
Enabled
Host Hardware Monitoring – VM Component Protection: “Protect against Storage Connectivity Loss”
Disabled (по умолчанию)
Virtual Machine Monitoring
Опционально, по умолчанию "Disabled"
Admission Control
30-50% для CPU и Memory.
Host Isolation Response
Power off and restart VMs
Datastore Heartbeats
Выбрать "Use datastores only from the specified list", но не выбирать ни одного хранилища из списка
Ну и должны быть добавлены следующие Advanced Settings:
Не так давно мы писали о гиперконвергентной платформе StarWind Hyper-Converged Platform (H-CP), которая позволяет построить полноценную ИТ-инфраструктуру небольшого предприятия на базе продуктов компаний StarWind, Veeam, VMware и Microsoft. H-CP поставляется в виде уже готовых к использованию серверов с предустановленными компонентами от соответствующих вендоров.
15 октября в 15:00ИТ-ГРАД проводит презентацию новых высокопроизводительных флеш-массивов AFF от NetApp. На мероприятии вы узнаете о новой расширенной линейке флеш-массивов СХД, разработанной для корпоративных клиентов. Спикерами мероприятия выступят инженеры NetApp и ИТ-ГРАД.
Компания VMware на днях сделала доступными видеозаписи основных докладов с прошедшей недавно конференции VMware VMworld 2015, где было сделано множество интересных анонсов.
Компания VMware выпустила обновление для прошлой версии платформы виртуализации - vSphere 5.5 Update 3. Не секрет, что большое количество компаний еще использует версию 5.5, так как на больших предприятиях процесс апгрейда ПО и лицензий протекает очень медленно. Поэтому данное обновление им будет весьма кстати.
Что нового в VMware vSphere 5.5 Update 3:
Управление механизмом ротации логов - теперь можно задавать ограничение по размеру лог-файлов в vmx (для каждого лога) и количество хранимых логов.
Сертификация адаптера PVSCSI – теперь устройство виртуальных дисков PVSCSI можно использовать для кластеров MSCS, а также кластеризации приложений, таких как Microsoft SQL или Exchange. Это позволит существенно повысить производительность по сравнению с адаптерами LSI Logic SAS.
Поддержка новых процессоров серверов - теперь платформа поддерживает последние поколения процессоров от Intel и AMD. Подробнее об этом написано в VMware Compatibility Guide.
Аутентификация серверов ESXi в Active Directory – ESXi поддерживает шифрование AES256-CTS/AES128-CTS/RC4-HMAC для коммуникации Kerberos между ESXi и Active Directory.
Поддержка новых баз данных - теперь vCenter Server поддерживает следующие СУБД:
Oracle 12c R1 P2 (12.1.0.2)
Microsoft SQL Server 2012 Service Pack 2
Microsoft SQL Server 2008 R2 Service Pack 3
Поддержка новых операционных систем - новые гостевые ОС теперь полностью поддерживаются:
CentOS 7.0
Oracle Linux 7.0
Ubuntu 14.10
Windows 10
RHEL 6.6
RHEL 7 .1
CentOS 7.1
Oracle Linux 7.1
File Transfer Log – теперь в лог-файлы пишется информация о файлах, переданных на хост ESXi или загруженных с него через vSphere Web Client или vSphere Client.
Также были обновлены несколько сопутствующих продуктов для виртуальной инфраструктуры. Вот ссылки:
Мы уже не раз писали о возможностях средства VMware vRealize Log Insight (например, тут и тут) для автоматизированного управления файлами журналов, а также сбора различных данных, их анализа и поиска. На прошедшей недавно конференции VMworld 2015 компания VMware анонсировала мажорный релиз этого средства - Log Insight 3.0.
Давайте взглянем на новые возможности продукта:
1. Возможности Log Insight 3 для больших инсталляций.
Не секрет, что продукт Log Insight ориентирован на большие инфраструктуры, где требуется централизованно обрабатывать и осуществлять поиск по сотням, а иногда и даже десяткам тысяч логов. Теперь решение обрабатывает в два раза больший объем данных в секунду (до 15 тысяч событий) на один узел. Максимальное число узлов кластера vRealize Log Insight также возросло - теперь 12 узлов могут обрабатывать 2,7 ТБ данных в день!
2. Улучшения движка аналитики.
К ним можно отнести:
Многофункциональные диаграммы - на одном графике можно выводить функции MIN, MAX и AVG для различных сущностей.
Интерактивные снапшоты аналитики - теперь можно визуализовать историю просмотра логов и использовать функцию "снапшота" запросов. Вы можете сравнить два разных запроса в снапшотах или использовать их для создания новых дэшбордов.
URL Shortener - обрезалка урлов, чтобы можно было удобно посылать ссылки на интерактивную аналитику коллегам.
События группируются по типам (объединяются одним цветом), что позволяет быстрее распознать характер события.
Тренды событий - теперь можно устанавливать кастомный диапазон времени и бэйслайны для них.
3. Улучшенные функции администрирования.
Здесь появились следующие нововведения:
Подхватывание роли мастер-узла другим узлом в случае временной или постоянной недоступности первого.
Возможность обновления без простоя одной кнопкой - при апгрейде узла он выводится из кластера, после чего обновляется на новую версию (при этом балансировщик в данной архитектуре не нужен).
Возможность форвардинга событий по UDP - теперь события syslog могут пересылаться не только по TCP.
Архивирование данных напрямую на Hadoop Distributed Filesystem (HDFS).
4. Легкий агент сбора данных для различных систем.
Здесь имеется в виду вот что:
Возможность массовой конфигурации агентов путем применения настроек на группу (из GUI).
Использование парсеров на стороне клиента (с возможностью задания паттернов распознавания логов в зависимости от настроек и локали).
Теперь события syslog посылаются по защищенному каналу SSL.
5. Улучшения документации.
Документ по резервному копированию и восстановлению конфигураций можно посмотреть вот тут.
vRealize Log Insight 3.0 GA Configuration Limits доступны по этой ссылке.
Скачать VMware vRealize Log Insight 3.0 можно по этой ссылке.

 RSS
RSS